



我的业务
-
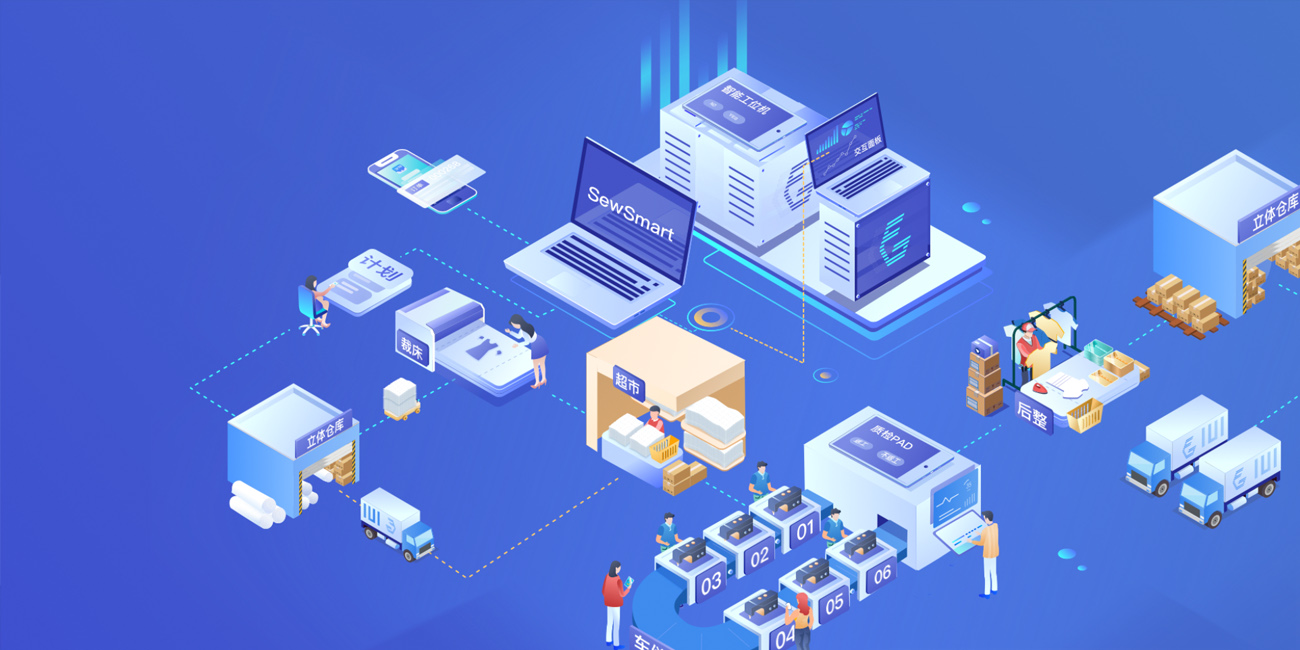 服装生产管理软件
服装生产管理软件 -
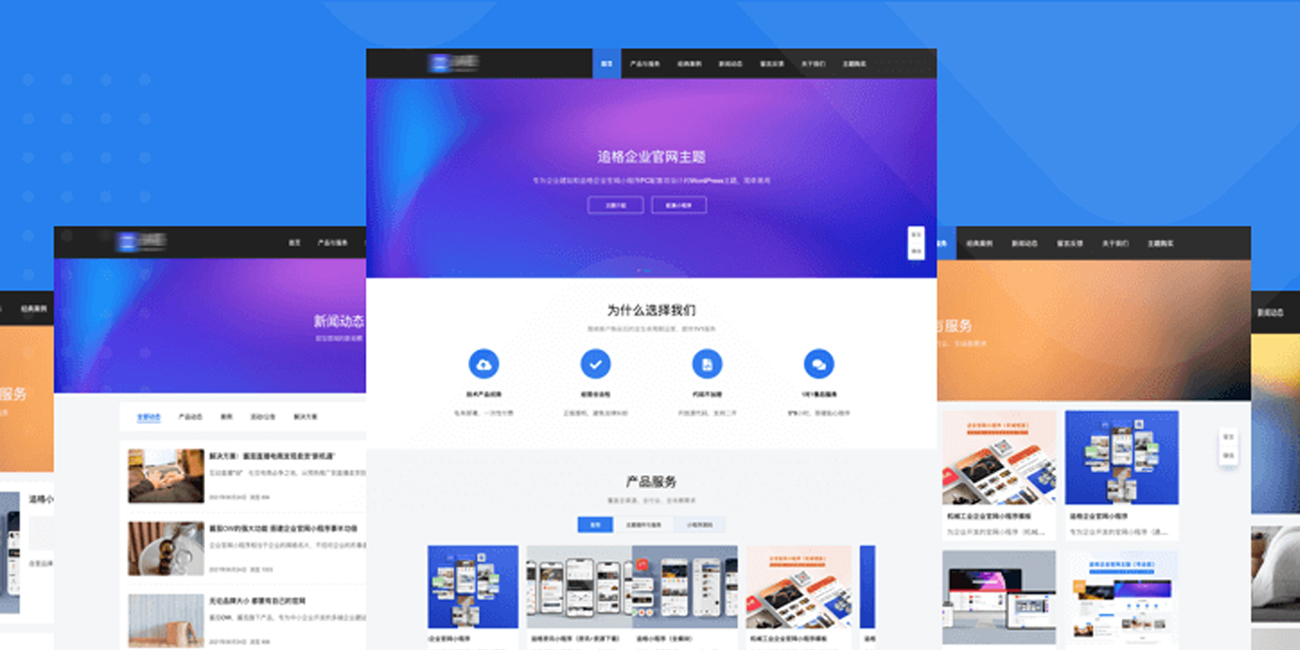 企业官网建设
企业官网建设 -
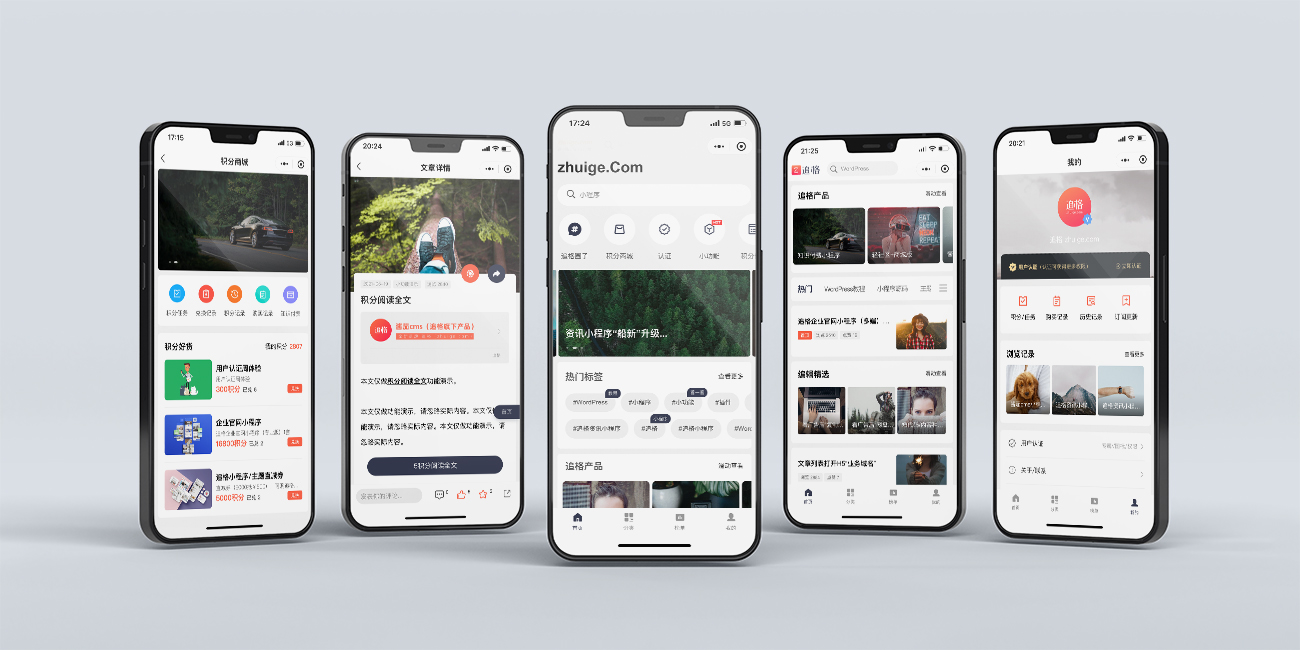 小程序制作开发
小程序制作开发

1,图片信息里导入图片,然后文生图 我的原图是512*512 2,尺寸需要先设置宽或者高,比如我这里先把高度设置1024 (不能同时设置宽和高,要不会直接把图片放大,而不是扩图) 重点设置controlnet里的参数 4.接着,点击图生图,去设置宽度成1024
2023-09-08SD绘画
使用到的大模型 meinamix_meinaV11.safetensors 提示词参考 正向 1man,smile,a grin on one’s face,silky smooth skin,(masterpiece:1,2),best quarity,masterpiece,high […]
2023-09-07SD绘画
我的是MacBook电脑,Windows也差不多的安装 主要参考教程: https://www.bilibili.com/video/BV1Bg4y1N77v/?spm_id_from=333.337.search-card.all.click&vd_source=2b7ba387338f3 […]
2023-09-03SD绘画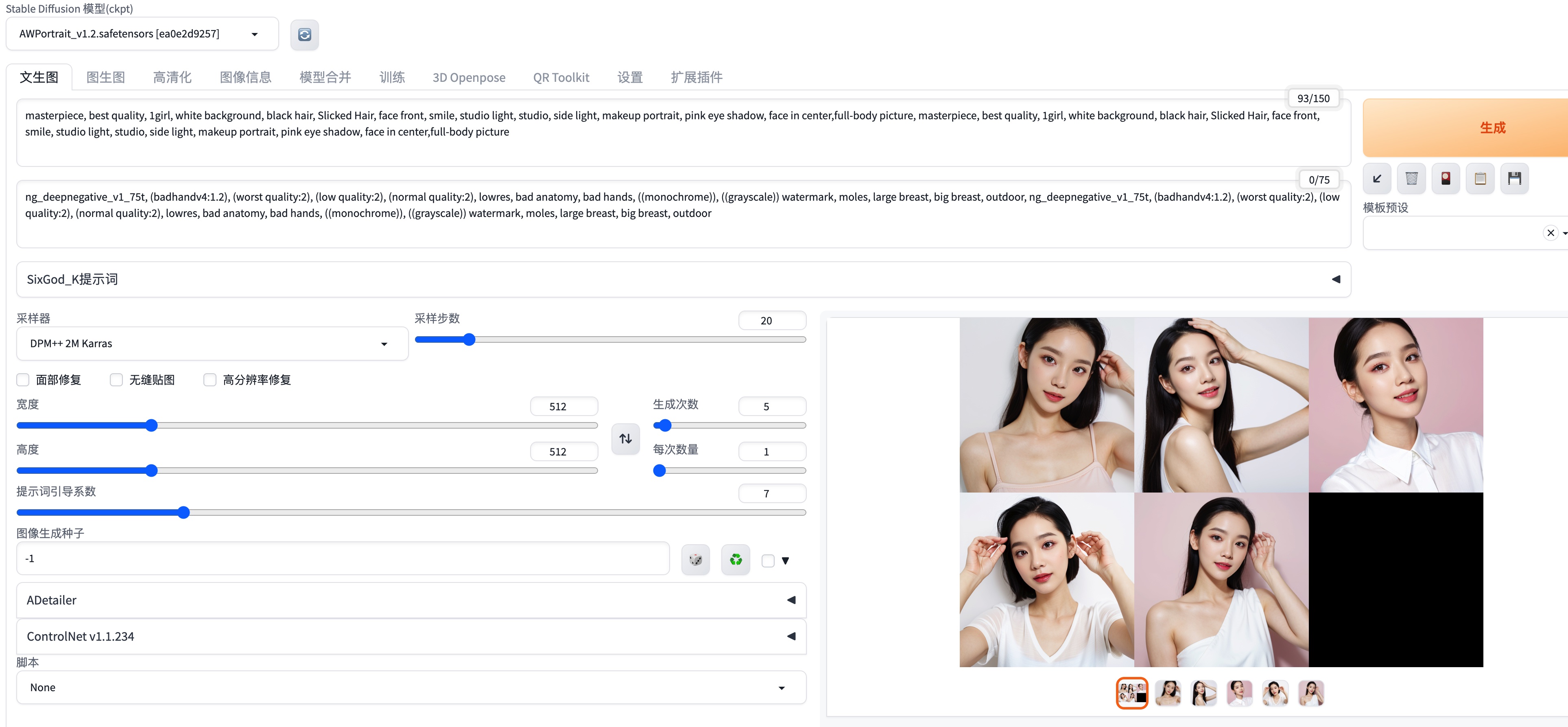
AWPortrait1.2 模拟影棚人像摄影效果的stable disffusion出图
参考教程:https://www.liblibai.com/modelinfo/721fa2d298b262d7c08f0337ebfe58f8 使用到的模型:AWPortrait1.2 正向提示词 负向提示词
2023-08-30SD绘画openapi.security.msgSecCheck在环境共享下无法调用的解决方案
小程序A,将云开发环境共享给小程序B,在小程序B里调用共享的云函数,里面调用openapi.security.msgSecCheck做文本检测,接口返回errCode:43104,openapi.security.msgSecCheck:fail The openid does not match […]
2023-08-26微信小程序=============其他代码块使用 this.data.c1
2023-08-26微信小程序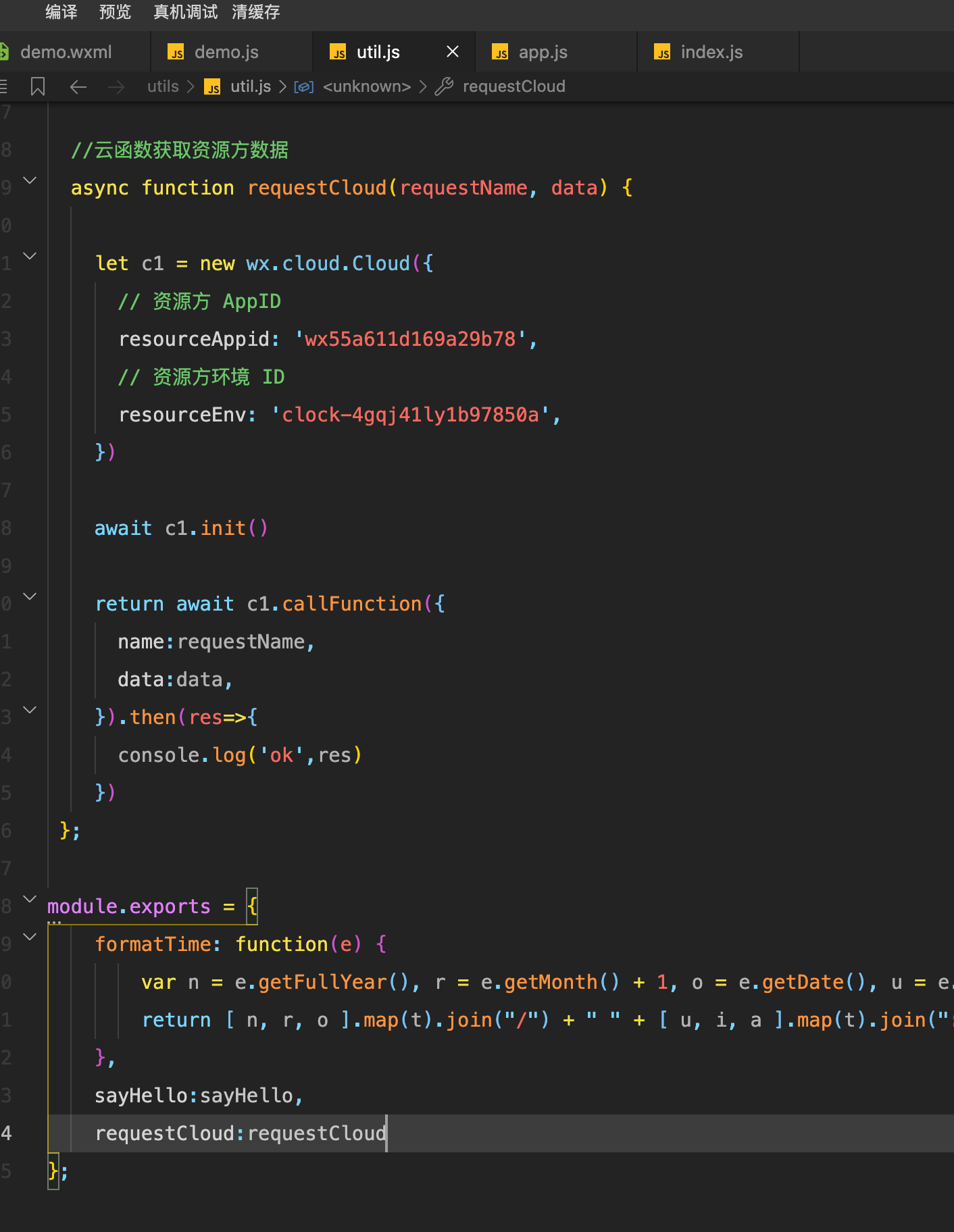
app.js代码编写,初始化云环境 util.js代码编写 引用页面文件
2023-08-26微信小程序 2023-08-03SD绘画
2023-08-03SD绘画
Overlooking the city from a high altitude, the grand and epic cityscape, high-rise buildings, film-like texture, modernist architecture is amazing, vi […]
2023-08-01SD绘画- 2023-05-16JavaScript


DU
DU,80后,误入互联网,终身学习者,博客分享自己的学习记录和生活点滴,随心记录,胡乱折腾。任何业务上的合作欢迎加V:iiamdu
云服务器大促销


明道云零代码企业应用平台

联系站长
友情链接
其他入口
QQ与微信加好友
粤ICP备17018681号 站点地图 www.iamdu.com 版权所有 服务商提供:阿里云 Designed by :DU
本站部分资源内容来源于网络,若侵犯您的权益,请联系删除!