



我的业务
-
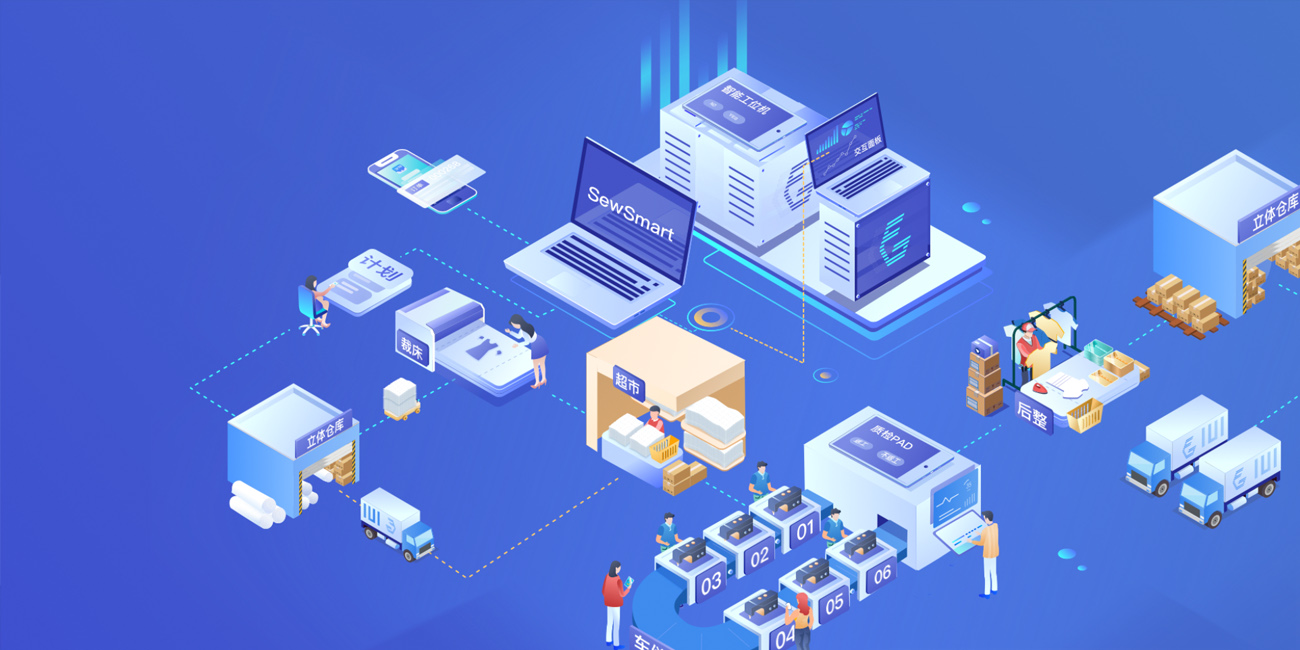 服装生产管理软件
服装生产管理软件 -
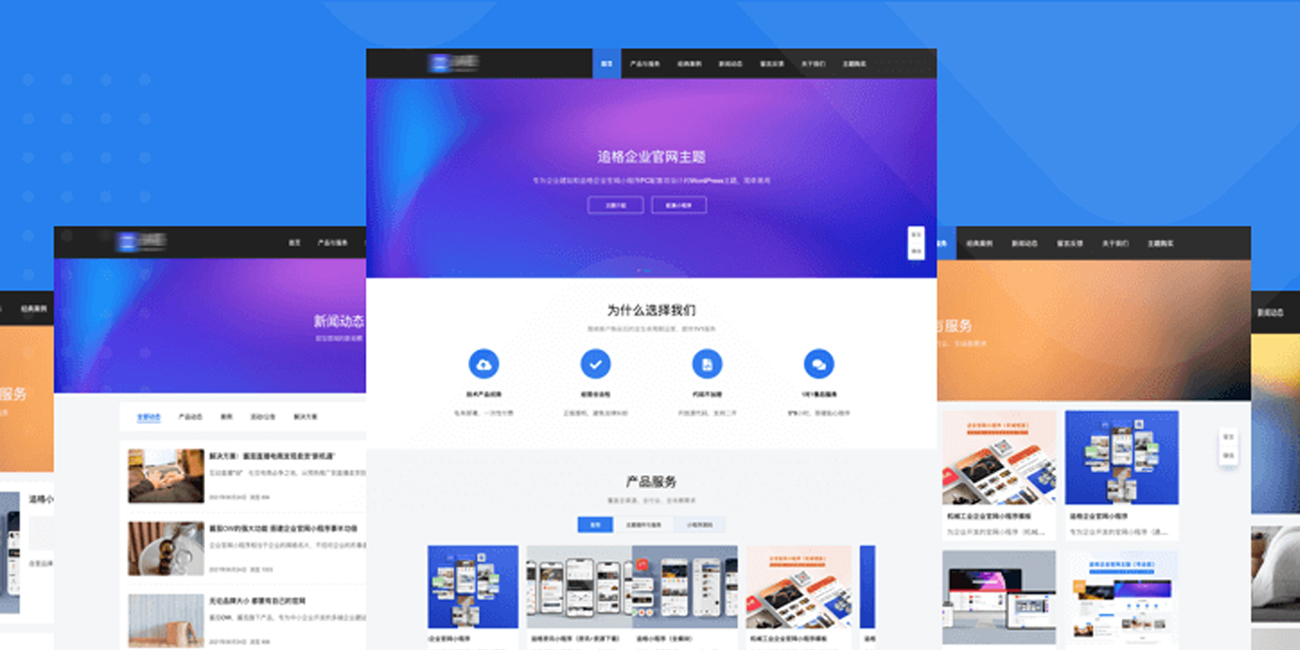 企业官网建设
企业官网建设 -
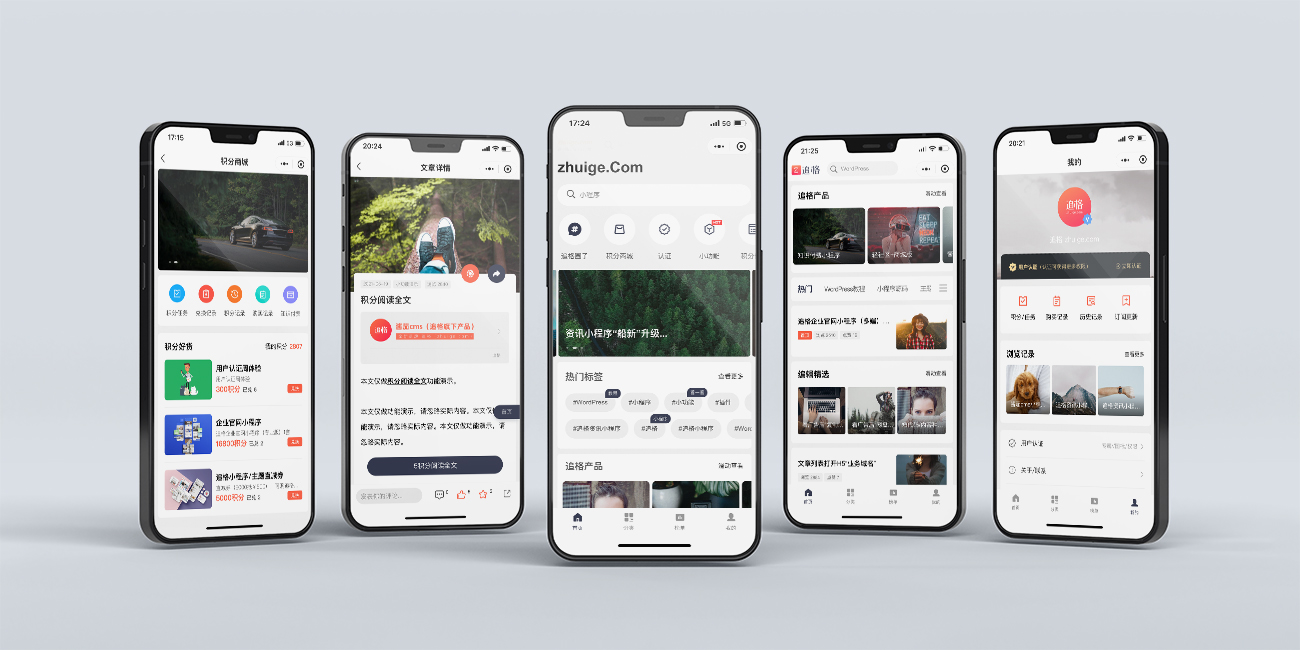 小程序制作开发
小程序制作开发
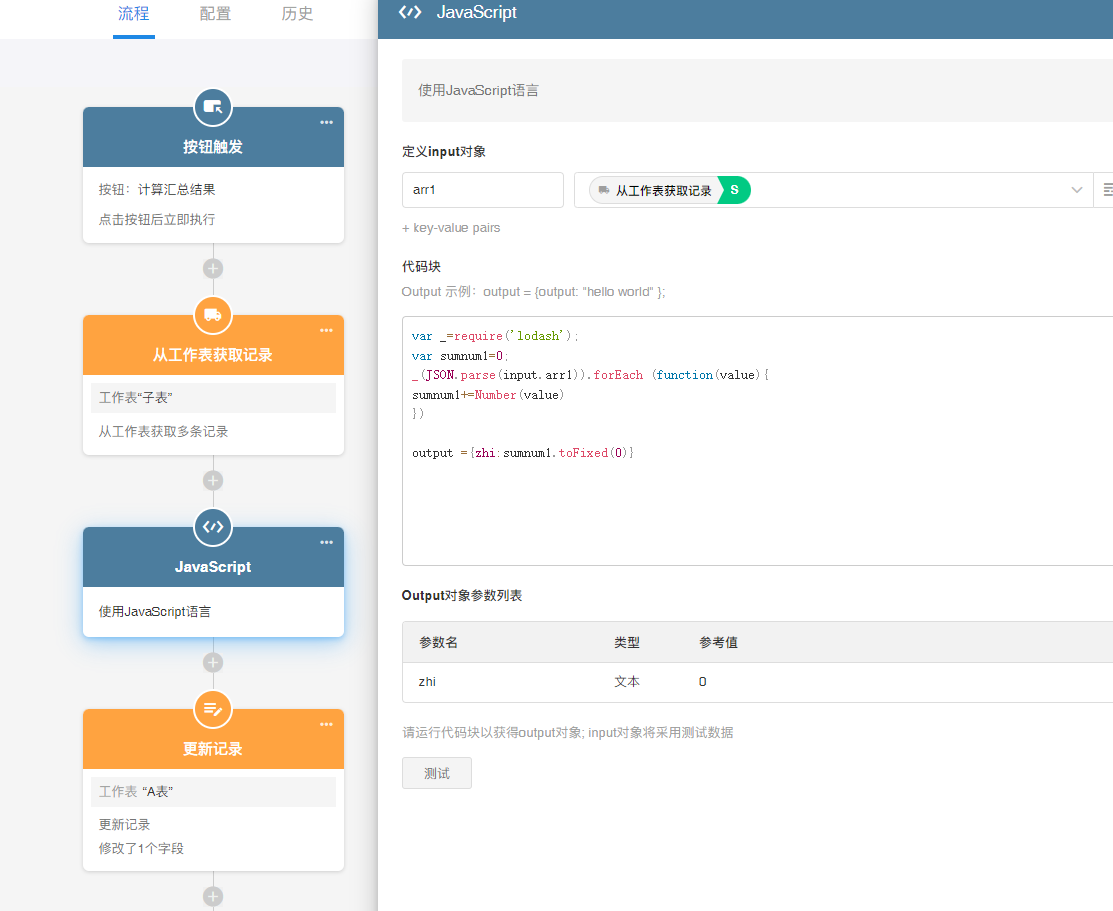
备注:只能对数值型的字段求和,公式型字段会报错
2023-04-29明道云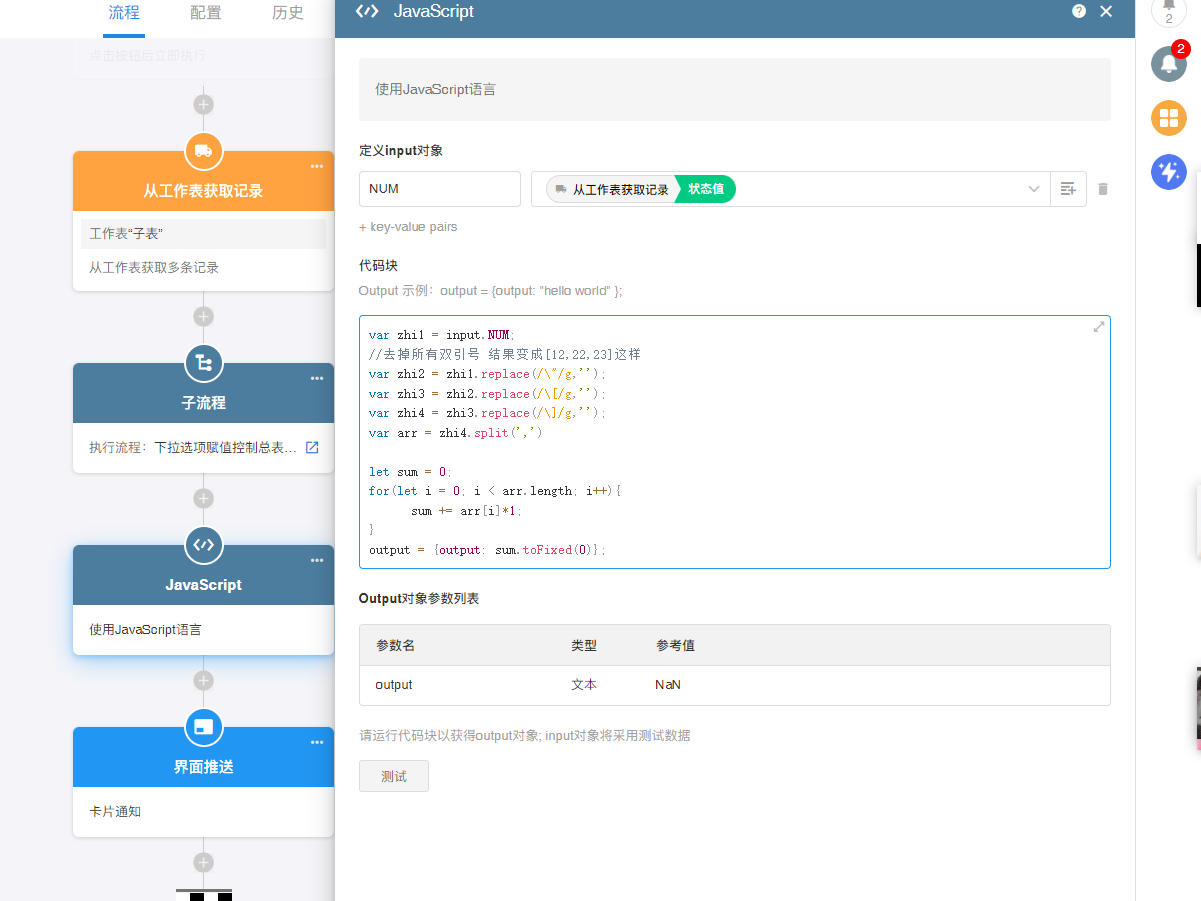 2023-04-19明道云
2023-04-19明道云在确保composer安装成功的前提下执行下面指令 composer create-project topthink/think tp6 该指令的执行速度和网速有关,请耐心等一会好吗?,执行期间可以看看下面指令中各个参数的解释。 指令中各个参数的解释 create-project: 是compose […]
2022-11-15PHP前端页面 PHP处理文件
2022-11-13PHP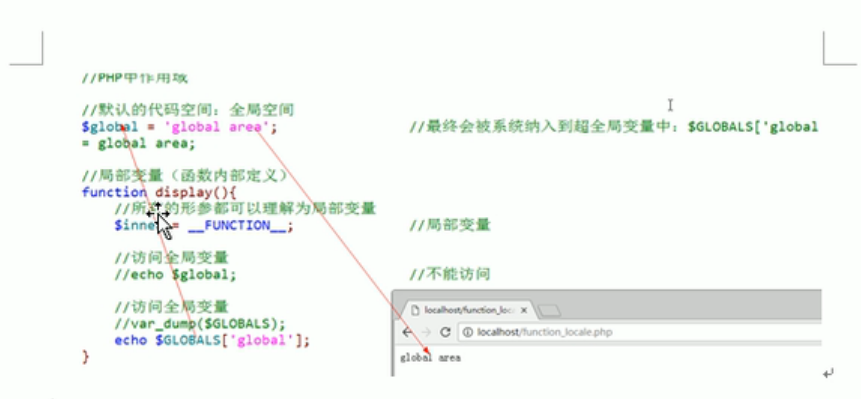
或者
2022-11-12PHP- 2022-08-12VUE
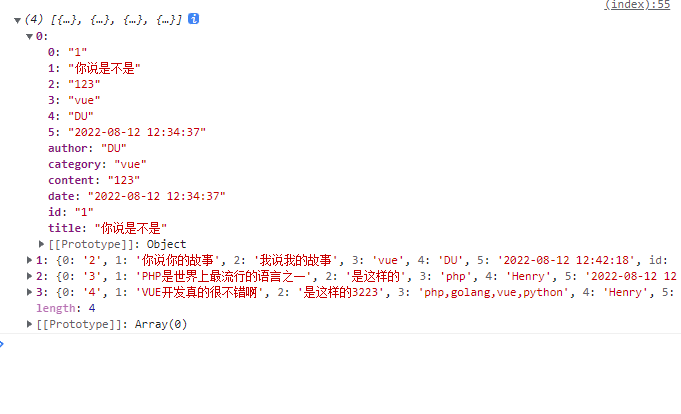 2022-08-12PHP
2022-08-12PHPPHP如何接受axios传递的参数 我们在做vue项目的时候一般都用axios发送请求,那后端php怎么接受前端传递的数据呢?举个例子,用户登录 axios.post(‘/api/user/loginin’, { username: this.username, passwo […]
2022-08-12VUE用上面的代码即可 然后运行 nodemon xxx.js 既可以热启动了 npm 和 cnpm 的区别 (1) 两者之间只是 node 中包管理器的不同。(2) npm是node官方的包管理器。cnpm是个中国版的npm,是淘宝定制的 cnpm (gzip 压缩支持) […]
2022-06-22nodejs- 2022-06-21golang


DU
DU,80后,误入互联网,终身学习者,博客分享自己的学习记录和生活点滴,随心记录,胡乱折腾。任何业务上的合作欢迎加V:iiamdu
云服务器大促销


明道云零代码企业应用平台

联系站长
友情链接
其他入口
QQ与微信加好友
粤ICP备17018681号 站点地图 www.iamdu.com 版权所有 服务商提供:阿里云 Designed by :DU
本站部分资源内容来源于网络,若侵犯您的权益,请联系删除!