
月度归档: 2019 年 12 月
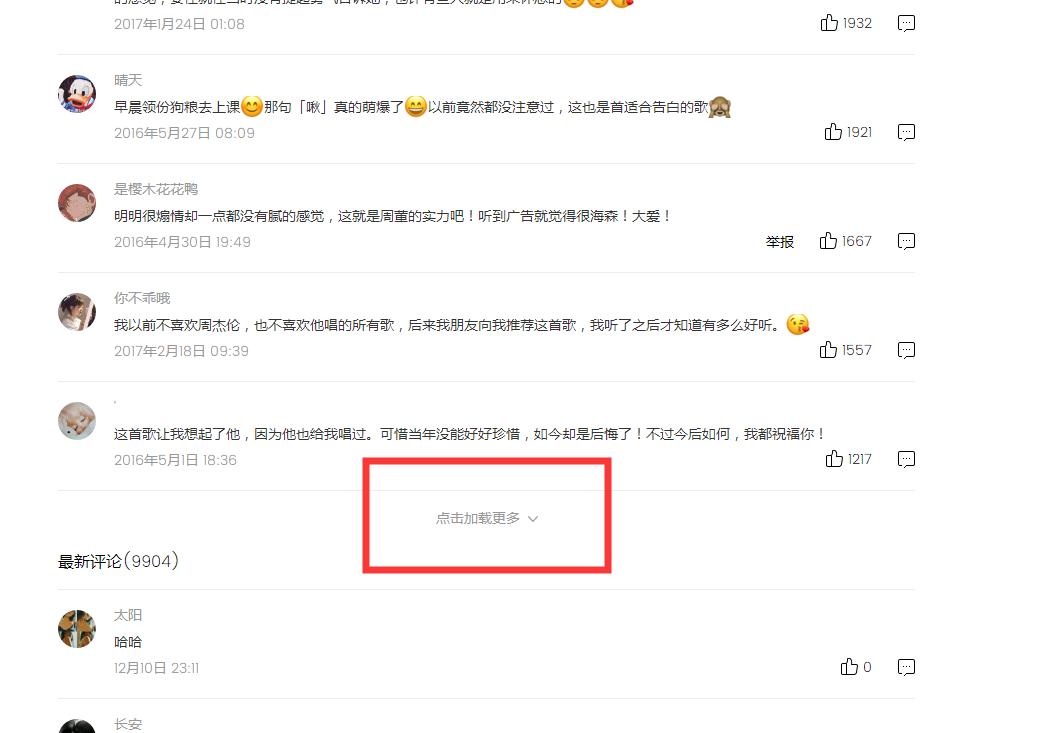
Python+selenium +BeautifulSoup抓取QQ音乐精彩评论(涉及点击加载更多的处理方式)
# 本地Chrome浏览器设置方法 from selenium import webdriver import time #本地一定得在环境根目录下安装谷歌浏览器的驱动 driver = webdriver.Chrome() from bs4 import BeautifulSoup import […]
2019-12-11Python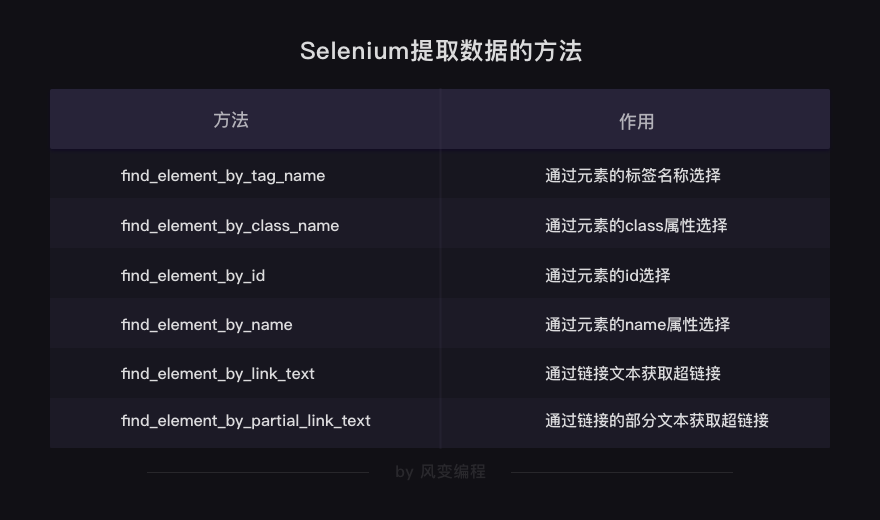
# 以下方法都可以从网页中提取出’你好,蜘蛛侠!’这段文字 find_element_by_tag_name:通过元素的名称选择 # 如<h1>你好,蜘蛛侠!</h1> # 可以使用find_element_by_tag_name(‘h1’) find_element_by_ […]
2019-12-10Python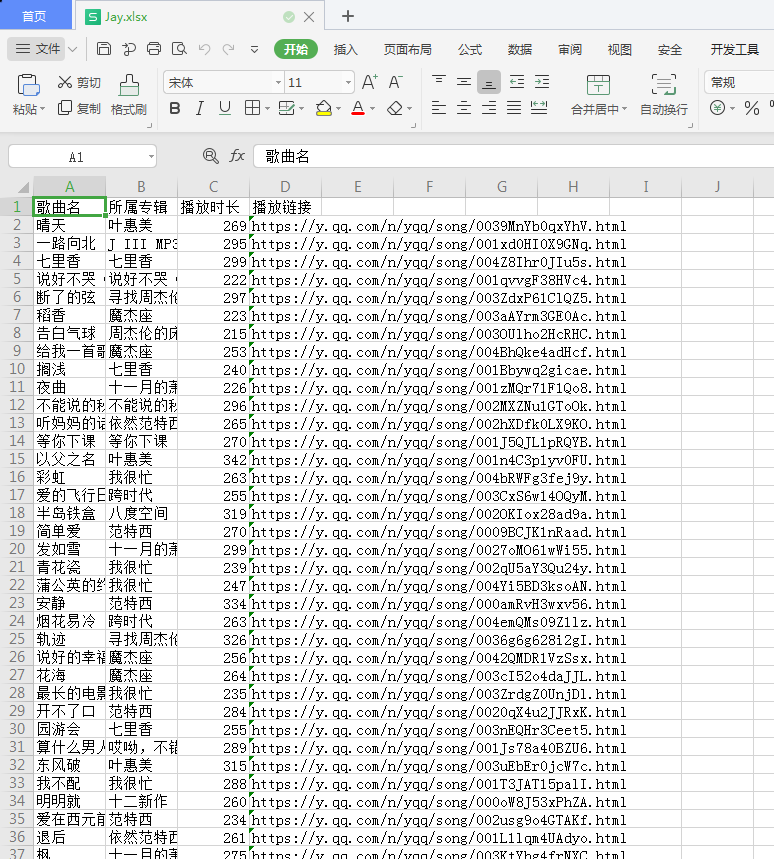
import requests,openpyxl # 创建工作薄 wb=openpyxl.Workbook() # 获取工作薄的活动表 sheet=wb.active # 工作表重命名 sheet.title=’lyrics’ sheet[‘A1′] =’歌曲名’ # 加表头,给A1单元格赋值 sh […]
2019-12-10Pythoncrv文件写入: # 引用csv模块。 import csv # 调用open()函数打开csv文件,传入参数:文件名“demo.csv”、写入模式“w”、newline=”、encoding=’utf-8’。 csv_file = open(‘demo.csv’,’w’,newline=”,e […]
2019-12-10Python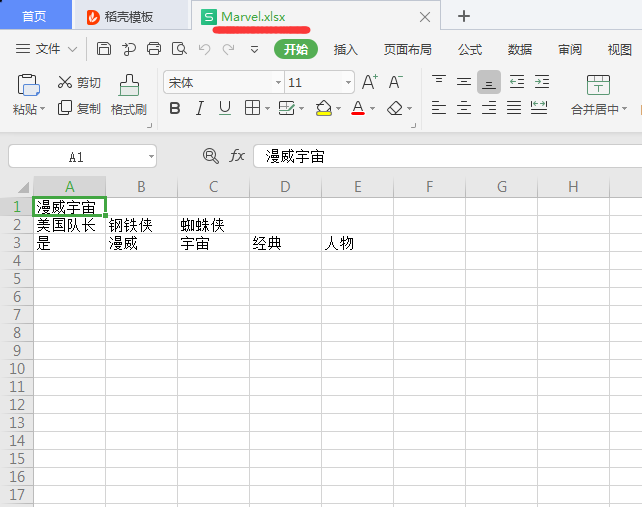
import openpyxl # 写入的代码: wb = openpyxl.Workbook() sheet = wb.active sheet.title = ‘new title’ sheet[‘A1’] = ‘漫威宇宙’ rows = [[‘美国队长’,’钢铁侠’,’蜘蛛侠’,’雷神’],[ […]
2019-12-10Python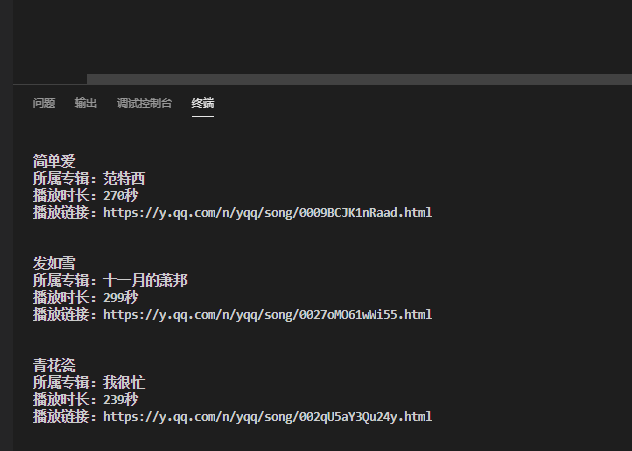
# 引用requests库 import requests # 调用get方法,下载这个字典 res_music = requests.get(‘https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298& […]
2019-12-10Python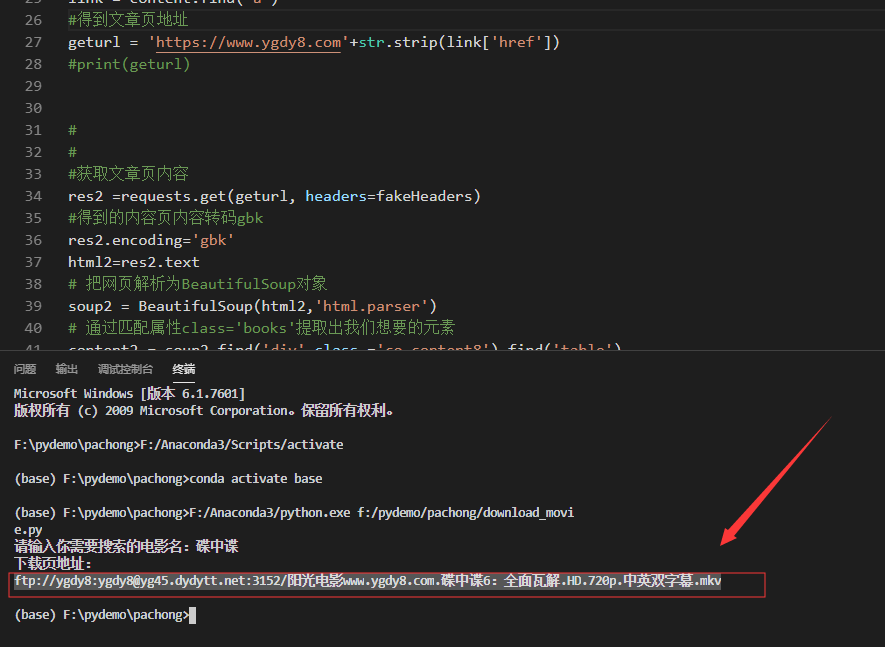
Python+BeautifulSoup抓取电影天堂影片下载地址
实现这样的功能:用户输入喜欢的电影名字,程序即可在电影天堂https://www.ygdy8.com爬取电影所对应的下载链接,并将下载链接打印出来。 #调用quote()函数 from urllib.parse import quote # 调用requests库 import requests # […]
2019-12-10Python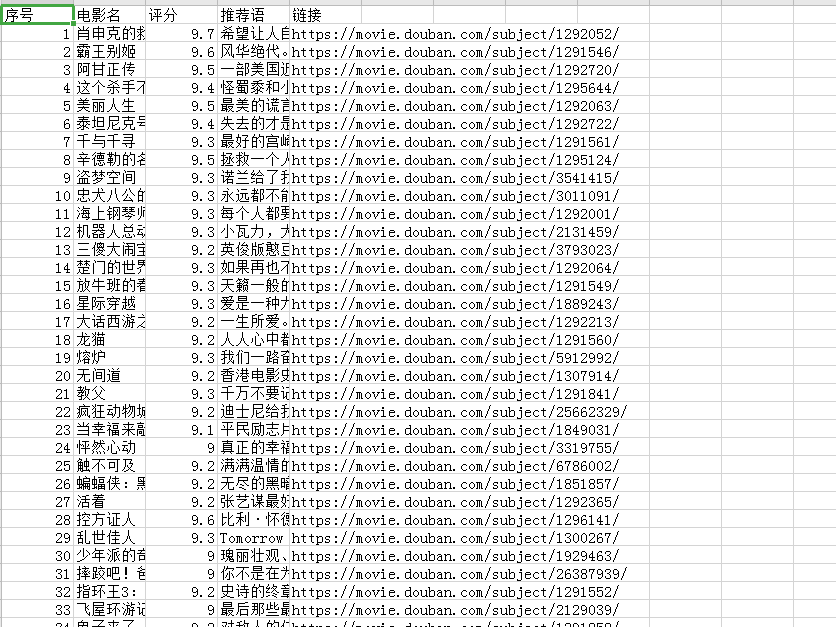
Python +BeautifulSoup 抓取豆瓣电影TOP250页面数据
#调用crv模块 最后把得到的数据写入crv import csv # 调用requests库 import requests # 调用BeautifulSoup库 from bs4 import BeautifulSoup # 模拟页头信息 fakeHeaders = {‘User-Agent’: […]
2019-12-10Python# 调用requests库 import requests # 调用BeautifulSoup库 from bs4 import BeautifulSoup # 返回一个response对象,赋值给res res =requests.get(‘https://localprod.pandateach […]
2019-12-09Python先看看print中逗号和加号分别打印出来的效果.. 这里以Python3为例 1 print(“hello” + “world”) helloworld 1 print(“hello”, “wor […]
2019-12-09Python
云服务器大促销


明道云零代码企业应用平台

联系站长
友情链接
其他入口
QQ与微信加好友
粤ICP备17018681号 站点地图 www.iamdu.com 版权所有 服务商提供:阿里云 Designed by :DU
本站部分资源内容来源于网络,若侵犯您的权益,请联系删除!