
Python+BeautifulSoup抓取电影天堂影片下载地址
实现这样的功能:用户输入喜欢的电影名字,程序即可在电影天堂https://www.ygdy8.com爬取电影所对应的下载链接,并将下载链接打印出来。
#调用quote()函数
from urllib.parse import quote
# 调用requests库
import requests
# 调用BeautifulSoup库
from bs4 import BeautifulSoup
# 模拟页头信息
fakeHeaders = {'User-Agent': "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)"}
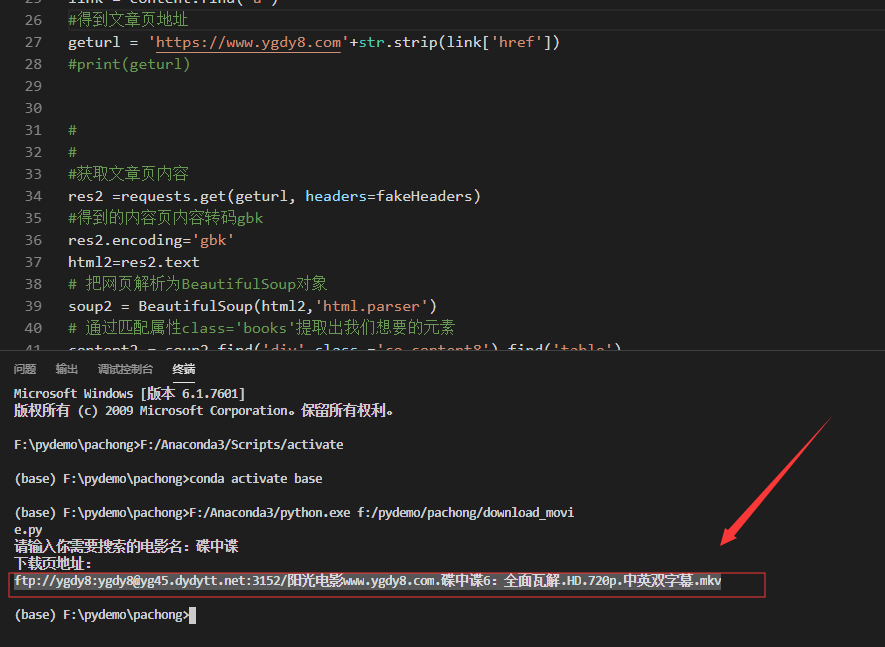
movie_name = input('请输入你需要搜索的电影名:')
# 将汉字,用gbk格式编码,赋值给whatname 因为电影天堂网站的编码是gbk 这里换成utf-8是搜索不到数据的
whatname = movie_name.encode('gbk')
#拼接搜索地址# quote()函数,可以帮我们把内容转为标准的url格式,作为网址的一部分打开
whaturl = 'http://s.ygdy8.com/plus/s0.php?typeid=1&keyword=' + quote(whatname)
#print(whaturl)
res =requests.get(whaturl, headers=fakeHeaders)
#print(res.status_code)
#得到搜索页内容
html=res.text
# 把网页解析为BeautifulSoup对象
soup = BeautifulSoup( html,'html.parser')
# 通过匹配属性class='books'提取出我们想要的元素
content = soup.find('div',class_='co_content8')
link = content.find('a')
#得到文章页地址
geturl = 'https://www.ygdy8.com'+str.strip(link['href'])
#print(geturl)
#
#
#获取文章页内容
res2 =requests.get(geturl, headers=fakeHeaders)
#得到的内容页内容转码gbk
res2.encoding='gbk'
html2=res2.text
# 把网页解析为BeautifulSoup对象
soup2 = BeautifulSoup(html2,'html.parser')
# 通过匹配属性class='books'提取出我们想要的元素
content2 = soup2.find('div',class_='co_content8').find('table')
link2 = content2.find('a')
#输出下载页地址
print('下载页地址:')
print(str.strip(link2['href']))
云服务器大促销


明道云零代码企业应用平台


欢迎留下你的看法
共 0 条评论