
作者: iamdu
宝塔面板Linux环境-安装Golang:Go语言环境安装以及程序如何运行
简便的安装方法: 1)安装go语言 宝塔面板安装go语言,方法如下:(如果有更新版本自己修改版本号~) 最新版本号可以去官方看看下载地址 官网:https://golang.google.cn/ wget https://golang.org/dl/go1.15.2.linux-amd64.tar. […]
2022-06-21golang
使用docker部署go项目 创建go项目 初始化一下项目 创建一个gin项目 创建一个gin项目,这里以gin为例,其他go项目都可以。 创建Dockerfile FROM golang:1.16-alpine: 将golang:1.16-alpine用作此 Docker 构建的基础镜像。 ENV […]
2022-06-21golang
install 会生成可执行文件
2022-06-20golang- 2022-06-17golang
 2022-06-14golang
2022-06-14golang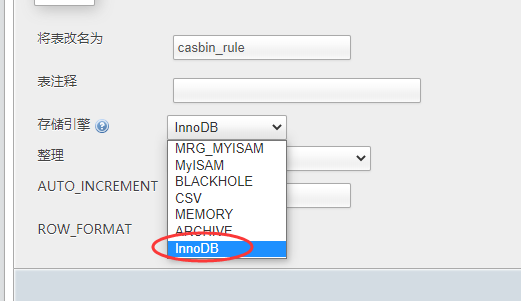
首次运行提示 Specified key was too long; max key length is 1000 bytes 解决:把存储引擎MyISAM 改成InnoDB ____________________________________________________ 问题2: 页面右键 […]
2022-06-14golang$(selector).remove(); 可以让页面元素不渲染出来,二前三种方法只是加了样式属性,。代码下还是可以看到的
2022-06-13CSSAJAX请求后新的数据点击无效,可以把 $(“.button”).click(function(){ 改成 $(document).on(‘click’, ‘.button’, function () { 即可
2022-06-11JavaScript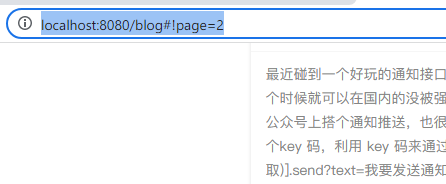
今天使用layui做分页功能,发现当直接输入网址访问的时候,#!page=2 服务器端无法获取page的值,如果改成?page=2 服务器端就能正确取值,但是研究了layui的参数发现无法把#!改成? 于是换个思路吧,地址栏打开的时候,通过前端JS获取到地址栏里的page值,通过Ajax异步请求加载 […]
2022-06-11layui
思维导图 Gin 简介 Gin is a HTTP web framework written in Go (Golang). It features a Martini-like API with much better performance – up to 40 times faster. I […]
2022-06-09golang
云服务器大促销


明道云零代码企业应用平台

联系站长
友情链接
其他入口
QQ与微信加好友
粤ICP备17018681号 站点地图 www.iamdu.com 版权所有 服务商提供:阿里云 Designed by :DU
本站部分资源内容来源于网络,若侵犯您的权益,请联系删除!