
涉及字体加密的爬虫分析
1.网页分析
爬虫嘛,最主要还是先分析分析网页。
首先,用谷歌浏览器打开“实习僧网站”,输入“数据挖掘”搜索,然后检查以下内容:
- 网页的加载方式:发现是纯静态加载的,说明数据就在html文件里;
- 如何翻页:通过观察发现网站是通过URL的参数“k”控制职位关键字,参数“p”控制页码,所以“数据挖掘”职位第一页的请求URL是“https://www.shixiseng.com/interns?k=数据挖掘&p=1”,“数据挖掘”职位第二页的请求URL是“https://www.shixiseng.com/interns?k=数据挖掘&p=2”,以此类推;
- 请求方法:GET
- 是否需要验证头信息:不晓得,需要代码测试
2.代码测试
那就来测试一下。
首先在实习僧中搜索“数据挖掘”,并打开IPython,把requests库导入进来。
import requests第一页长这样:

尝试请求一下第一页, 把状态码打出来看看。
response = requests.get(“https://www.shixiseng.com/interns?k=数据挖掘&p=1”)print(response.status_code)状态码是200,喜出望外,心想这网站也太好爬了吧,竟然连头信息都不需要验证。有点不敢相信,想再瞅一眼文本内容。
print(response.text[:100])确实返回了真实的文本,这就好办了,尝试解析一下,提取出所有的职位名称,这里使用的是xpath选择器。
from lxml import etreeparsed_text = etree.HTML(response.text)parsed_text.xpath(‘//*[@class="name-box clearfix"]/a/text()’)成功返回一个列表的数据,大功告。。。wait,好像有点不大对劲,这夹杂在文字当中的是啥玩意儿?网站给我投毒了?
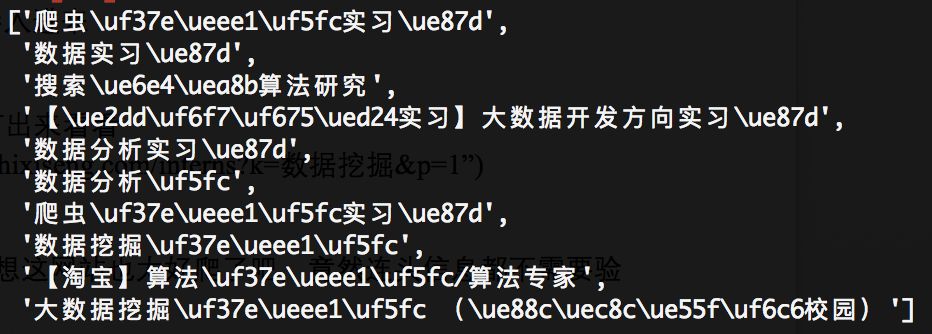
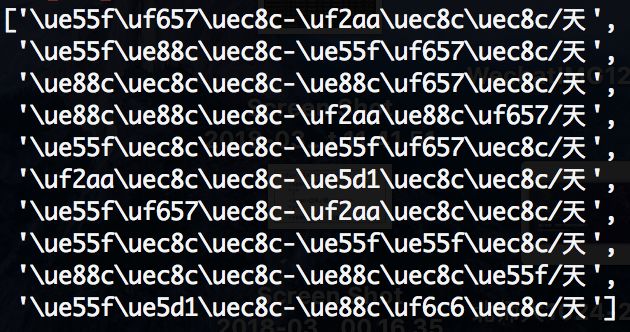
第一反应是编码问题,但是想想也不对啊,要是编码问题的话,怎么又有一部分中文可以显示呢?再测试了一下薪酬,问题更严重,数字全都无法正常显示。
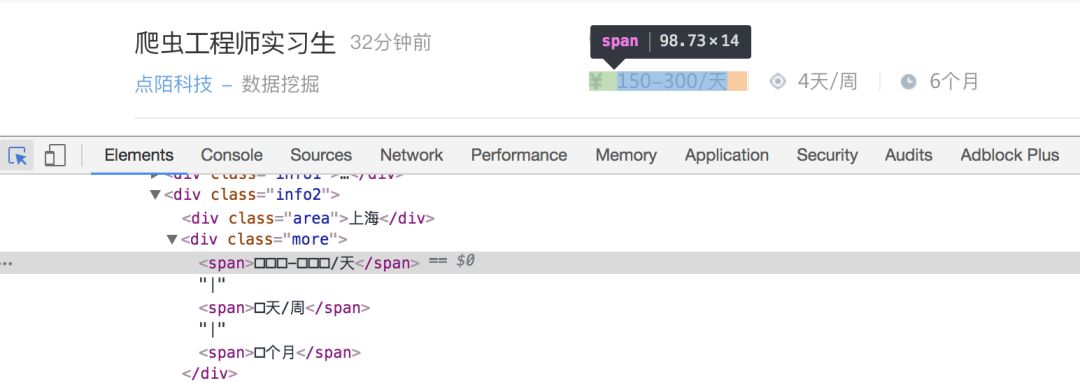
在元素检查窗口发现,这些都显示成了小框框,怎么办呢?
3.寻找解决办法
秉着不被打脸的想法以及按捺不住的好奇,我打开了网页源代码,看看这个显示为框框的字符,在源代码里是怎么显示的。发现数字在里面又被显示成:

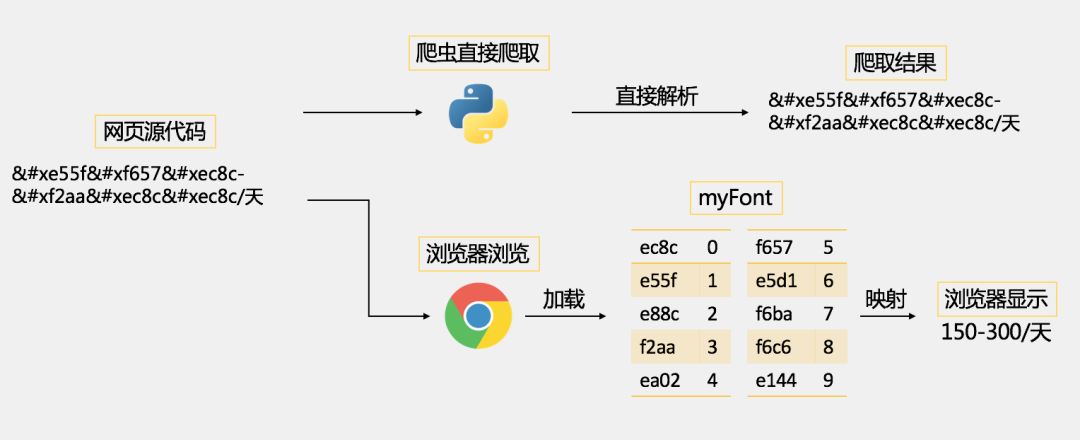
这才反应过来,应该是字体被加密了。再翻了翻网页源代码,在<style>标签里发现了“font-family:myFont”这玩意儿,更印证了我的猜想:

这后面的一长串乱码,便是经过base64加密的“自定义unicode-字符映射”字体,正常浏览网页时被浏览器加载进网页。
因此,为了防止爬虫采集网站数据,可爱的前端工程师可以自己创建一套自己的字体,也就是这里的myFont,设置自定义的unicode-字符映射关系,比如说这里的“ec8c”映射的是字符“0”,“e55f”映射的是字符“1”等等(这个映射关系是可以自定义的),并通过base64加密一下,放进网页源代码中。
当某些数据需要防止爬虫爬取时,便指定使用myFont这个自定义字体,因此,正常浏览时,网页中的字体会被映射成正常的123…的数字,但是网页源代码中却是自定义的编码,爬虫采集的是网页源代码,所以采集到的也是自定义的编码,采集不到正常的数据。
如何解决?
其实方法有很多:
- 第一种是破译映射关系:把刚刚那一长串加密的文字弄下来,用base64解一下码(在Python中可以使用pybase64包),保存为.ttf字体文件,然后使用fontforge找字符的映射关系。不过这种方法稍微有些麻烦了。具体可见:传送门1:http://www.freebuf.com/news/140965.html;
- 第二种方法是图片文字识别:也看到有人实现了,即使用自动化测试工具selenium定位到数据,使用PIL图像处理包截图保存数据,然后使用机器学习或者OCR识别出图片中的文字。这种方法就更加麻烦了。如果使用机器学习的话,还需要人工打标,训练数据不大的话效果还不太理想,想一想画面很美,还是算了。具体可见:传送门2:https://jizhi.im/blog/post/maoyan-anti-crawler;
- 第三种更加直接:由于需要寻找的字符映射并不多(最主要是找到数字的映射),如果每次所爬网页加载的字符映射关系是不变(或者一段时间内不变)的话,直接观察网页寻找字符映射关系应该更加快捷,也更加巧(bao)柔(li)。我当然是毫不犹豫地选择了第三种。
4.寻找映射
于是,开搞!
通过比对发现,“实习僧网站”每次网页加载的字符映射确实是一段时间内不变的。那么只需要观察网页源代码与对应的浏览器显示的数字,便可找到映射关系。
把最终找到的数字映射关系保存为一个字典(注意,根据观察,这个映射关系好像是每天更新一次,所以需要自己去找这个映射,不能照抄):
mapping = {'': '0', '': '1', '': '2', '': '3', '': '4', '': '5', '': '6', '': '7', '': '8', '': '9'}出于万全的考虑,还结合了一下第一种方法寻找映射关系并进行比对。不过我还是偷了懒取了个巧,具体操作方法是把base64解码保存的.ttf字体文件转为.svg格式,导入到 IcoMoon(一个Web字体图标制造器,传送门3:https://icomoon.io/app/#/select )查看。
嘿,发现结果如下:

这里便是“实习僧网站”所有进行自定义映射的字符,发现数字全部都进行了映射加密, 还有大小写字母。
同时,还有小部分跟职位有关的字,比如说“工”、“程”、“师”等也都被加密了,这就是第一条记录的职位“爬虫工程师实习生”会被显示成“爬虫\uf37e\ueee1\uf5fc实习\ue87d”的原因。
那为什么不把全部的字体都进行加密呢?
还是因为中文字体库太大的原因,所以只加密了很小一部分的职位关键字。不过我需要进行爬取的中文文字信息,比如说职位名称,在职位详情页和公司详情页都有未加密的,可以直接爬取,所以只找数字的映射关系就OK了。利用IcoMoon找到的数字映射关系如下:

发现跟我使用人工寻找的映射关系完全一致。说明寻找映射关系大功告成。接下来便是定爬取目标和写代码的事情了。
5.兢兢业业写代码
爬取目标:
- 爬取“数据挖掘”、“机器学习”两个职位下的实习信息
- 爬取搜索记录中每条职位记录的职位详情页的职位信息
- 爬取搜索记录中每条职位记录对应的公司详情页的公司信息
搜索发现数据这两个职位的数据并不太多,秉着杀鸡不用牛刀的想法,就直接使用requests写好了,懒得使用Scrapy。接下来略讲一下代码的关键函数,其它的详细代码就见Github链接吧。
首先,定义一个爬取的函数,参数为需要爬取的职位:job,以及这个职位总共的页数:pages。我们运行这个函数的时候,只需要传入职位和页数便可爬取这个职位所有页数的数据,并且保存到csv文件中。
另外,定义了一个文本处理函数decrypt_text(),根据之前找到的mapping来处理requests请求返回回来的文本,主要如下:
def decrypt_text(text): # 定义文本信息处理函数,通过字典mapping中的映射关系解密 for key, value in mapping.items(): text = text.replace(key, value) return text另外,测试了一下,网站除了加密字体反爬之外,好像就没有其它的反爬限制了。所以,其它部分的代码基本上就是文本匹配的体力活。在这里就不赘述了。代码的关键步骤和函数都加上了注释,GitHub传送门为:https://github.com/Alfred1984/interesting-python。
最后便剩下调试运行啦。运行结果:
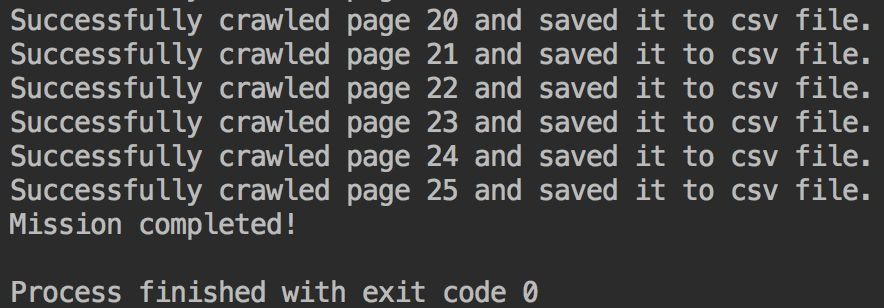
再看一眼.csv文件,比对一下数据是否可以对应上,确保网站没有给我投毒。发现数据是正确的。可以安心了。
最后爬取回来的数据(不要问Excel为什么打开是乱码):
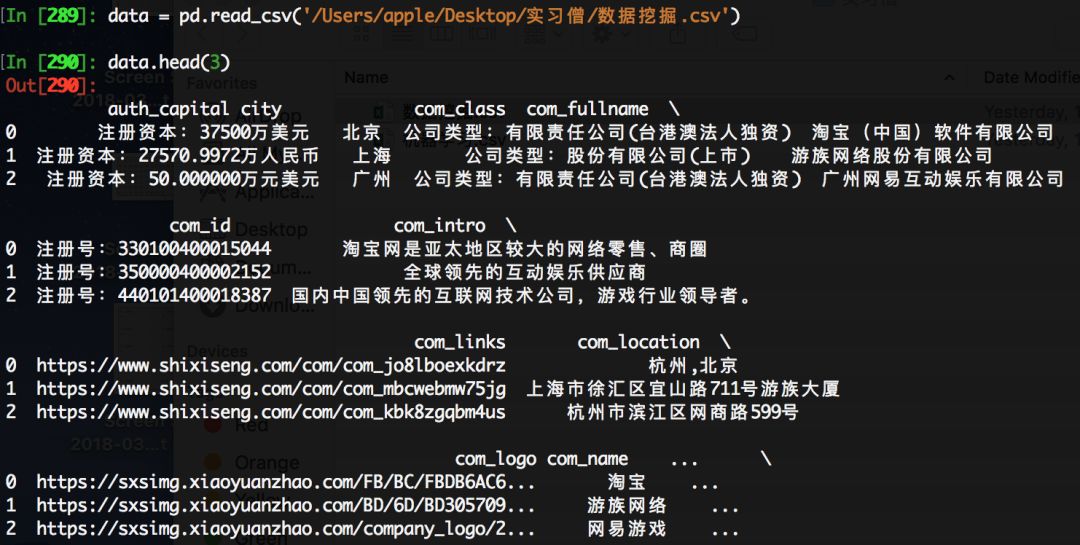
大功告成。可以对爬取回来的数据进行分析了。我比较贪心,把所有有关的信息都爬了下来,一共有27个字段,各种类型的字段都有,数据比较脏,需要清洗的地方也挺多的,写在一起篇幅太长了,就把数据分析的部分放在下一篇文章中吧。
云服务器大促销


明道云零代码企业应用平台

联系站长
友情链接
其他入口
QQ与微信加好友
粤ICP备17018681号 站点地图 www.iamdu.com 版权所有 服务商提供:阿里云 Designed by :DU
本站部分资源内容来源于网络,若侵犯您的权益,请联系删除!